0 前言
基于 centos7.9,docker-ce-20.10.18,kubelet-1.22.3-0
1 简介
基本概念
- 最小部署单元
- 一组容器的集合
- 一个 Pod 中的容器共享网络命名空间
- Pod 是短暂的
存在意义
Pod 为亲密性应用而存在。
亲密性应用场景:
- 两个应用之间发生文件交互
- 两个应用需要通过 127.0.0.1 或者 socket 通信(典型组合:nginx+php)
- 两个应用需要发生频繁的调用
2 pod 中的容器分类
- Infrastructure Container:基础容器,维护整个 Pod 网络空间
- InitContainers:初始化容器,先于业务容器开始执行
- Containers:业务容器,并行启动
Infrastructure Container
pod 中总会多一个 pause 容器,这个容器就是实现将 pod 中的所有容器的网络命名空间进行统一,a 容器在 localhost 或者 127.0.0.1 的某个端口提供了服务,b 容器访问 localhost 或者 127.0.0.1 加端口也可以访问到
pause 容器主要为每个业务容器提供以下功能:
- PID 命名空间:Pod 中的不同应用程序可以看到其他应用程序的进程 ID。
- 网络命名空间:Pod 中的多个容器能够访问同一个 IP 和端口范围。
- IPC 命名空间:Pod 中的多个容器能够使用 SystemV IPC 或 POSIX 消息队列进行通信。
- UTS 命名空间:Pod 中的多个容器共享一个主机名;Volumes(共享存储卷)。
Init container:
- 基本支持所有普通容器特征
- 优先普通容器执行
应用场景:
- 控制普通容器启动,初始容器完成后才会启动业务容器
- 初始化配置,例如下载应用配置文件、注册信息等
示例
apiVersion: v1
kind: Pod
metadata:
name: pod-init
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
initContainers:
- name: install
image: busybox
command: ["wget", "-O", "/work-dir/index.html", "http://www.baidu.com/index.html"]
volumeMounts:
- name: workdir
mountPath: "/work-dir"
volumes:
- name: workdir
emptyDir: {}
3 静态 pod
静态 Pod 特点:
- Pod 由特定节点上的 kubelet 管理
- 不能使用控制器
- Pod 名称标识当前节点名称
在 kubelet 配置文件启用静态 Pod:
vi /var/lib/kubelet/config.yaml
...
staticPodPath: /etc/kubernetes/manifests
...
将部署的 pod yaml 放到该目录会由 kubelet 自动创建
4 重启策略
Pod 的 spec 中包含一个 restartPolicy 字段,其可能取值包括 Always、OnFailure 和 Never。默认值是 Always。
restartPolicy 适用于 Pod 中的所有容器。
- Always:当容器终止退出后,总是重启容器,默认策略。
- OnFailure:当容器异常退出(退出状态码非 0)时,才重启容器。
- Never:当容器终止退出,从不重启容器。
5 健康检查
5.1 三种探针
kubernetes 包含以下三种探针
- livenessProbe(存活探针): 如果检查失败, 根据 Pod 的 restartPolicy 来决定是否重启 container.
- readinessProbe(就绪探针): 如果检查失败, 会把 Pod 暂时从 service endpoints 中剔除.
- startupProbe(启动探针): 如果检查失败, 根据 Pod 的 restartPolicy 来决定是否重启 container. 用于启动非常慢的应用.
需要注意的是, 如果容器未配置以上三种探针, 则视为三种探针皆为成功, liveness 和 readiness 探针的 initialDelaySeconds 配置代表 startup 探针成功后等待多少秒再去初始化 liveness 和 readiness 探针.
5.1.1 检查方法
支持以下四种检查方法:
- httpGet:对容器的 IP 地址上指定端口和路径执行 HTTP
GET请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的。 - exec:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
- tcpSocket:对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。 如果远程系统(容器)在打开连接后立即将其关闭,这算作是健康的。
- gRPC:使用 gRPC 执行一个远程过程调用。需要应用程序支持,参考
5.1.2 检查结果
- Success(成功)
- Failure(失败)
- Unknown(未知): 不会执行任何操作.
5.1.3 探针配置
- initialDelaySeconds: 容器启动后 (startup 探针成功) 要等待多少秒后存活和就绪探测器才被初始化, 默认是 0 秒, 最小值是 0.
- periodSeconds: 执行探测的时间间隔.默认是 10 秒, 最小值是 1.
- timeoutSeconds: 探测的超时后等待多少秒. 默认值是 1 秒. 最小值是 1.
- successThreshold: 探测器在失败后, 被视为成功的最小连续成功数. 默认值是 1. 存活探测的这个值必须是 1。最小值是 1.
- failureThreshold: 当 Pod 启动了并且探测到失败的重试次数. 存活探测情况下的放弃就意味着重新启动容器. 就绪探测情况下的放弃 Pod 会被打上未就绪的标签, 默认值是 3, 最小值是 1.
5.2 示例
5.2.1 liveness
linveness 实际触发重启需要的时间 = 失败次数 * 间隔时间 + 等待容器优雅退出的宽限期 (默认 30s,docker 默认是 10s)
failureThreshold * periodSeconds + terminationGracePeriodSeconds
livenessProbe 示例
apiVersion: v1
kind: Pod
metadata:
name: pod-livenessprobe
namespace: default
spec:
restartPolicy: OnFailure
terminationGracePeriodSeconds: 10
containers:
- name: liveness
image: busybox
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "touch /tmp/healthy; sleep 10; rm -rf /tmp/healthy; sleep 600"]
livenessProbe:
exec:
command: ["test", "-e", "/tmp/healthy"]
initialDelaySeconds: 5
periodSeconds: 5
failureThreshold: 2
运行结果可以看到在两分钟的时间里重启了 4 次,每次 30s
[root@k8s-node1 opt]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-pod 1/1 Running 4 (2s ago) 2m2s
- POD 运行的前 10s 检查一直成功
- 在 POD 启动的第 15s 第一次检查失败
- 第 20s 第二次检查失败,给容器发送停止信号
- 等待 10s 后强制重启容器
5.2.2 liveness-with-startup
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-probes
namespace: default
spec:
terminationGracePeriodSeconds: 10
containers:
- name: liveness-with-startup
image: busybox
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "sleep 5; touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"]
startupProbe:
exec:
command: ["test", "-e", "/tmp/healthy"]
periodSeconds: 5
failureThreshold: 10
livenessProbe:
exec:
command: ["test", "-e", "/tmp/healthy"]
initialDelaySeconds: 15
periodSeconds: 5
failureThreshold: 3
重启过程:
- POD 启动成功,触发 startup 探针
- 第 10 秒 startup 探针成功
- 第 25 秒后初始化 liveness 探针
- 第 40 秒 liveness 探针第一次失败
- 第 50 秒 liveness 探针第三次失败, 触发重启, 等待容器优雅退出
- 第 60 秒强制重启 container
6 lifecycle
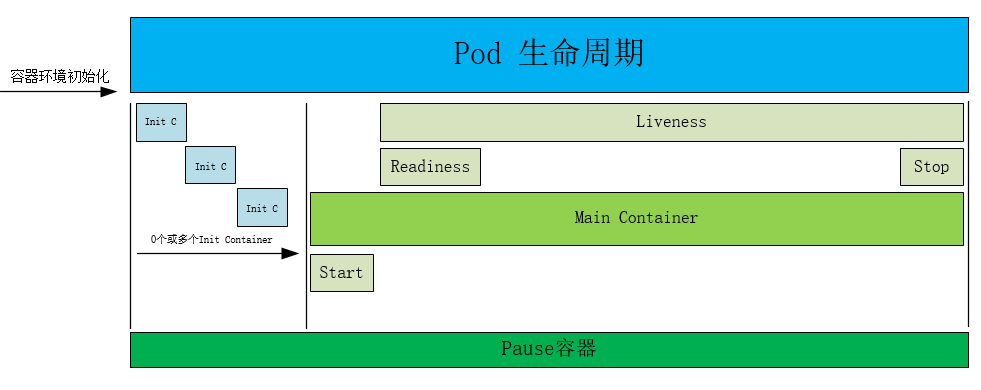
6.1 postStart 和 preStop
如下示例
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo-pod
namespace: default
labels:
test: lifecycle
spec:
containers:
- name: lifecycle-demo
image: nginx:1.22.1
imagePullPolicy: IfNotPresent
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo 'Hello from the postStart handler' >> /var/log/nginx/message"]
preStop:
exec:
command: ["/bin/sh", "-c", "echo 'Hello from the preStop handler' >> /var/log/nginx/message"]
volumeMounts:
- name: message-log
mountPath: /var/log/nginx/
readOnly: false # 读写挂载方式,默认为读写模式false
initContainers:
- name: init-myservice
image: busybox:1.28
command: ["/bin/sh", "-c", "echo 'Hello initContainers' >> /var/log/nginx/message"]
volumeMounts:
- name: message-log
mountPath: /var/log/nginx/
readOnly: false # 读写挂载方式,默认为读写模式false
volumes:
- name: message-log
hostPath:
path: /data/volumes/nginx/log/
type: DirectoryOrCreate # 表示如果宿主机没有此目录则会自动创建
效果如下
[root@k8s-node1 ~]# kubectl delete pod lifecycle-demo-pod
[root@k8s-node2 log]# cat message
Hello initContainers
Hello from the postStart handler
Hello from the preStop handler
以上

