0 前言
基于 centos7.9,docker-ce-20.10.18,kubelet-1.22.3-0
1 滚动升级
1.1 实现机制
滚动升级的实现机制
两个 replicaset 控制器分别控制旧版本的 pod 和新版本 pod,replicaset2 启动一个新版版本 pod,相应的 replicaset1 停止一个旧版本 pod,从而实现滚动升级。在这过程中,无法保证业务流量完全不丢失。
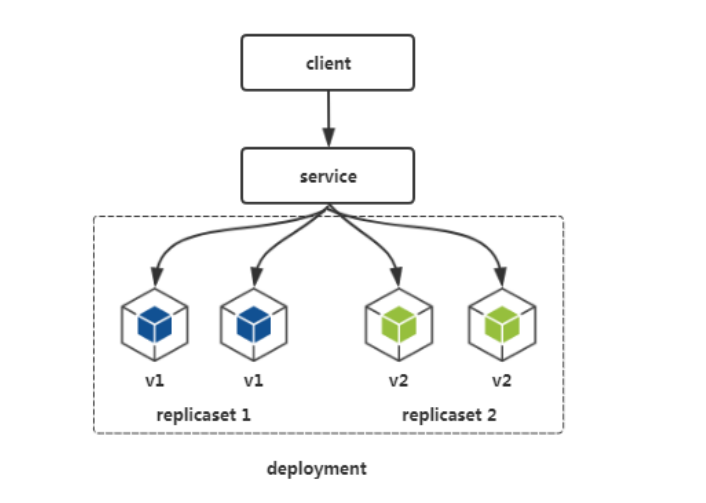
1.2 简单示例
升级
kubectl set image (-f FILENAME | TYPE NAME) CONTAINER_NAME_1=CONTAINER_IMAGE_1 ... CONTAINER_NAME_N=CONTAINER_IMAGE_N [options]
# 示例
kubectl set image deployment/demo-rollout nginx=nginx:1.15 --record=true
# --record=true 表示将升级的命令记录到升级记录中
回滚
# 上次升级状态
kubectl rollout status deployment demo-rollout
# 升级记录
kubectl rollout history deployment demo-rollout
# 回滚至上个版本
kubectl rollout undo deployment demo-rollout
# 回滚至指定版本
kubectl rollout undo deployment demo-rollout --to-revision=2
1.3 升级
在所有 work 节点先创建几个 busybox 镜像的 tag 用于升级演示
[root@k8s-node3 ~]# for i in {1..3}; do docker tag busybox:latest busybox:v${i}; done
[root@k8s-node3 ~]# docker images | grep busybox
busybox latest 7cfbbec8963d 3 weeks ago 4.86MB
busybox v1 7cfbbec8963d 3 weeks ago 4.86MB
busybox v2 7cfbbec8963d 3 weeks ago 4.86MB
busybox v3 7cfbbec8963d 3 weeks ago 4.86MB
创建 v1 版本的 deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-rollout
labels:
app: demo-rollout
spec:
replicas: 3
selector:
matchLabels:
app: demo-rollout
template:
metadata:
labels:
app: demo-rollout
spec:
containers:
- name: busybox
image: busybox:v1
command: ['/bin/sh', '-c', 'sleep 36000']
也可以使用命令创建
[root@k8s-node1 ~]# kubectl create deployment demo-rollout --image=busybox:v1 --replicas=3 -- sleep 3600
deployment.apps/demo-rollout created
[root@k8s-node1 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
demo-rollout-5d847fd86c-678pr 1/1 Running 0 4s
demo-rollout-5d847fd86c-9mj4v 1/1 Running 0 4s
demo-rollout-5d847fd86c-xhvf7 1/1 Running 0 4s
升级至 v2 和 v3
# 升级
[root@k8s-node1 ~]# kubectl set image deployment/demo-rollout busybox=busybox:v2 --record=true
[root@k8s-node1 ~]# kubectl set image deployment/demo-rollout busybox=busybox:v3 --record=true
# 查看升级状态
[root@k8s-node1 ~]# kubectl rollout status deployment demo-rollout
deployment "demo-rollout" successfully rolled out
[root@k8s-node1 ~]# kubectl rollout history deployment demo-rollout
deployment.apps/demo-rollout
REVISION CHANGE-CAUSE
1 <none>
2 kubectl set image deployment/demo-rollout busybox=busybox:v2 --record=true
3 kubectl set image deployment/demo-rollout busybox=busybox:v3 --record=true
# 查看实际镜像版本
[root@k8s-node1 ~]# kubectl get deployment demo-rollout -o jsonpath='{.spec.template.spec.containers}'
[root@k8s-node1 ~]# kubectl describe deployment demo-rollout | grep -i image:
Image: busybox:v3
1.4 回滚
回滚至 v1 版本
[root@k8s-node1 ~]# kubectl rollout undo deployment/demo-rollout --to-revision=1
deployment.apps/demo-rollout rolled back
[root@k8s-node1 ~]# kubectl describe deployment demo-rollout | grep -i image:
Image: busybox:v1
[root@k8s-node1 ~]# kubectl rollout history deployment demo-rollout
deployment.apps/demo-rollout
REVISION CHANGE-CAUSE
2 kubectl set image deployment/demo-rollout busybox=busybox:v2 --record=true
3 kubectl set image deployment/demo-rollout busybox=busybox:v3 --record=true
4 <none>
可以看到 rollout history 删除了第一次的记录, 重新记录到第四条
恢复到 v2 版本
[root@k8s-node1 ~]# kubectl rollout undo deployment/demo-rollout --to-revision=2
deployment.apps/demo-rollout rolled back
[root@k8s-node1 ~]# kubectl describe deployment demo-rollout | grep -i image:
Image: busybox:v2
[root@k8s-node1 ~]# kubectl rollout history deployment demo-rollout
deployment.apps/demo-rollout
REVISION CHANGE-CAUSE
3 kubectl set image deployment/demo-rollout busybox=busybox:v3 --record=true
4 <none>
5 kubectl set image deployment/demo-rollout busybox=busybox:v2 --record=true
2 自动伸缩
手动扩容
kubectl scale [--resource-version=version] [--current-replicas=count] --replicas=COUNT (-f FILENAME | TYPE NAME) [options]
# 示例
kubectl scale deployment demo-rollout --replicas=10
自动扩容
实现自动扩容需满足两个条件:
- 运行了 metric-server
- pod 设置了 request 资源
Horizontal Pod Autoscaling: pod 水平扩容,k8s 中的一个 api 资源,使用 autoscale 时会创建一个 hpa 资源
HPA 基本原理:
- 查询指定的资源中所有 Pod 的资源平均使用率,并且与创建时设定的值和指标做对比,从而实现自动伸缩的功能.
- HPA 自动伸缩副本时会使 POD 的资源使用率趋近于预设的 target 值
- 比如只有一个 POD 时, 资源使用率达到了 180%/70%, HPA 会将 POD 数量扩容到 3 个, 此时资源使用率将会是 60%/70%.
- 当 pod 资源使用率回到正常水平, controller-manager 会默认等待 5 分钟的时间再缩容 pod,以免再次出现突发流量.
kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min=MINPODS] --max=MAXPODS [--cpu-percent=CPU] [options]
# 基于cpu指标进行扩容
kubectl autoscale deployment demo-rollout --min=3 --max=10 --cpu-percent=10
# 查看hpa
kubectl get hpa
# replicaset控制器记录了pod的详细伸缩记录
kubectl get rs
kubectl describe rs demo-rollout-54fdcc5676
2.1 基于 CPU
创建 deployment 资源
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
resources:
requests:
memory: 50Mi
cpu: 50m
---
apiVersion: v1
kind: Service
metadata:
name: hpa-demo
labels:
app: nginx
spec:
selector:
app: nginx
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30002
创建 hpa 资源
cpu 使用率 = 已使用 / request
--cpu-percent=60 代表所有 pod 的平均 cpu 使用率达到百分之 60 时触发扩容
[root@k8s-node1 ~]# kubectl autoscale deployment hpa-demo --cpu-percent=60 --min=1 --max=10
horizontalpodautoscaler.autoscaling/hpa-demo autoscaled
[root@k8s-node1 ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 0%/60% 1 10 1 18s
压测
[root@k8s-node1 ~]# yum install -y httpd-tools
[root@k8s-node1 ~]# ab -n 1000000 -c 200 http://1.1.1.1:30002/
hpa 自动扩容, pod 数量增加到了 10 个
[root@k8s-node1 ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 160%/10% 1 10 10 50m
[root@k8s-node1 ~]# kubectl describe hpa hpa-demo
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetScale 17m (x8 over 19m) horizontal-pod-autoscaler deployments/scale.apps "hpa-demo" not found
Normal SuccessfulRescale 11m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 11m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 10m horizontal-pod-autoscaler New size: 10; reason:
[root@k8s-node1 ~]# kubectl describe deployment hpa-demo
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 16m deployment-controller Scaled up replica set hpa-demo-6b4467b546 to 1
Normal ScalingReplicaSet 10m deployment-controller Scaled up replica set hpa-demo-6b4467b546 to 4
Normal ScalingReplicaSet 9m53s deployment-controller Scaled up replica set hpa-demo-6b4467b546 to 8
Normal ScalingReplicaSet 9m38s deployment-controller Scaled up replica set hpa-demo-6b4467b546 to 10
压测结束后也并不会立即减少 pod 数量,会等一段时间后减少 pod 数量,防止流量再次激增。默认时间大概是 5 分钟左右
2.2 基于内存
使用 busybox 容器测试, 另挂载一个 configMap 用于内存压力测试, 由于用到了 mount 命令, 还需要将 container 声明为特权模式.
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-mem
spec:
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- name: busybox
image: busybox
command: ["/bin/sh", "-c", "sleep 36000"]
volumeMounts:
- name: increase-mem-script
mountPath: /opt/
resources:
requests:
memory: 50Mi
cpu: 50m
securityContext:
privileged: true
volumes:
- name: increase-mem-script
configMap:
name: increase-mem-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: increase-mem-config
data:
increase-mem.sh: |
#!/bin/sh
mkdir /tmp/memory
mount -t tmpfs -o size=40M tmpfs /tmp/memory
dd if=/dev/zero of=/tmp/memory/block
sleep 60
rm /tmp/memory/block
umount /tmp/memory
rmdir /tmp/memory
获取 hpa 的模板 yaml 文件
[root@k8s-node1 ~]# kubectl autoscale deployment hpa-mem --min=1 --max=10 --dry-run=client -o yaml > hpa-mem-hpa.yml
[root@k8s-node1 ~]# vim hpa-mem-hpa.yml
使用 yaml 创建 hpa, 默认使用的是 autoscaling/v1 版本的 api, 它不支持基于内存的自动扩容, 需要修改为 autoscaling/v2beta1
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: hpa-mem
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-mem
metrics:
- type: Resource
resource:
name: memory
targetAverageUtilization: 60
执行脚本进行压测, 随着脚本执行, hpa 自动将副本数扩容到了两个
[root@k8s-node1 ~]# kubectl exec -it hpa-mem-c6c7d4957-fpsfb -- /bin/sh /opt/increase-mem.sh
[root@k8s-node1 ~]# kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-mem Deployment/hpa-mem 0%/60% 1 10 1 2m55s
hpa-mem Deployment/hpa-mem 80%/60% 1 10 1 4m1s
hpa-mem Deployment/hpa-mem 80%/60% 1 10 2 4m16s
脚本执行 60s 后会使内存使用率自动恢复正常, 副本数过段时间也会自动恢复
2.3 基于自定义指标
待续……
以上

